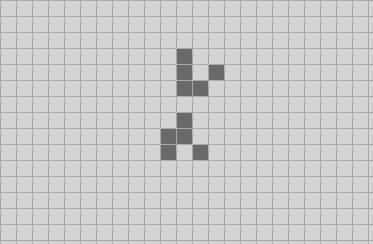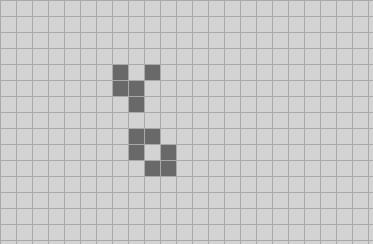All right, we have our quad data structure, we know how to get and set individual elements, and we know how to display it. We’ve deduplicated it using memoization. How do we step it forward one tick? (Code for this episode is here.)
Remember a few episodes ago when we were discussing QuickLife and noted that if you have a 2-quad in hand, like these green ones, you can get the state of the blue 1-quad one tick ahead? And in fact we effectively memoized that solution by simply precomputing all 65536 cases.

The QuickLife algorithm memoized only the 2-quad-to-center-1-quad step algorithm; we’re going to do the same thing but with even more memoization. We have a recursively defined quad data structure, so it makes sense that the step algorithm will be recursive. We will use 2-quad-to-1-quad as our base case.
For the last time in this series, let’s write the Life rule:
private static Quad Rule(Quad q, int count)
{
if (count == 2) return q;
if (count == 3) return Alive;
return Dead;
}
We’ll get all sixteen cells in the 2-quad as numbers:
private static Quad StepBaseCase(Quad q)
{
Debug.Assert(q.Level == 2);
int b00 = (q.NW.NW == Dead) ? 0 : 1;
... 15 more omitted ...
and count the neighbours of the center 1-quad:
int n11 = b00 + b01 + b02 + b10 + b12 + b20 + b21 + b22;
int n12 = b01 + b02 + b03 + b11 + b13 + b21 + b22 + b23;
int n21 = b11 + b12 + b13 + b21 + b23 + b31 + b32 + b33;
int n22 = b10 + b11 + b12 + b20 + b22 + b30 + b31 + b32;
return Make(
Rule(q.NW.SE, n11),
Rule(q.NE.SW, n12),
Rule(q.SE.NW, n21),
Rule(q.SW.NE, n22));
}
We’ve seen this half a dozen times before. The interesting bit comes in the recursive step. The key insight is: for any n>=2, if you have an n-quad in hand, you can compute the (n-1) quad in the center, one tick ahead.
How? We’re going to use almost the same technique that we used in QuickLife. Remember in QuickLife the key was observing that if we had nine Quad2s in the old generation, we could compute a Quad3 in the new generation with sixteen steps on component Quad2s. The trick here is almost the same. Let’s draw some diagrams.
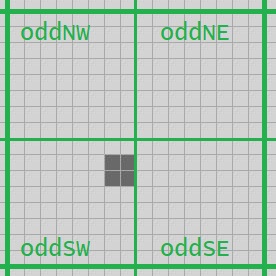
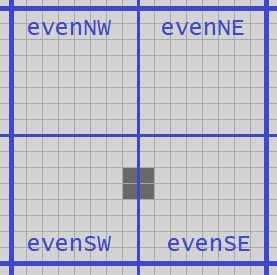
Suppose we have the 3-quad from the image above. We compute the next generation of its four component 2-quads; the green quads are current, the blue are stepped one ahead.
We can use a similar trick as we used with QuickLife to get the north, south, east, west and center 2-quads of this 3-quad, and move each of them ahead one step to get five more 1-quads. I’ll draw the original 3-quad in light green, and we can extract component 2-quads from it that I’ll draw in dark green. We then move each of those one step ahead to get the blue 1-quads.
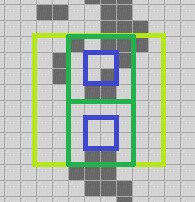
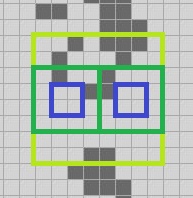

That gives us this information:

We then make four 2-quads from those nine: and extract the center 1-quad from each using the Center function (source code below). I’ll just show the northwest corner; you’ll see how this goes. We make the light blue 2-quad out of four of the blue 1-quads, and then the center 1-quad of that thing is:

We do that four times and from those 1-quads we construct the center 2-quad moved one step ahead:

Summing up the story so far:
- We can take a 2-quad forward one tick to make a 1-quad with our base case.
- We’ve just seen here that we can use that fact to take a 3-quad forward one tick to make a 2-quad stepped forward one tick.
- But nothing we did in the previous set of steps depended on having a 3-quad specifically. Assume that for some n >= 2 we can move an n-quad forward one tick to make an (n-1) quad; we have above an algorithm where we use that assumption and can move an (n+1)-quad forward to get an n-quad.
That is, we can move a 2-quad forward with our base case; moving a 3-quad forward requires the ability to move a 2-quad forward. Moving a 4-quad forward requires the ability to move a 3-quad forward, and so on.
As I’ve said many times on this blog, every recursive algorithm is basically the same. If we’re in the base case, solve the problem directly. If we’re not in the base case, break up the problem into finitely many smaller problems, solve each, and use the solutions to solve the larger problem.
Let’s write the code to move any n-quad for n >= 2 forward one tick.
We’ll need some helper methods that extract the five needed sub-quads, but those are easily added to Quad. (Of course these helpers are only valid when called on a 2-quad or larger.)
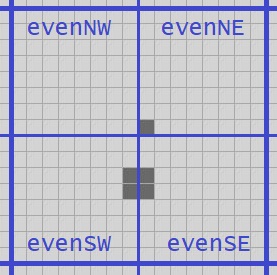
public Quad Center => Make(NW.SE, NE.SW, SE.NW, SW.NE);
public Quad N => Make(NW.NE, NE.NW, NE.SW, NW.SE);
public Quad E => Make(NE.SW, NE.SE, SE.NE, SE.NW);
public Quad S => Make(SW.NE, SE.NW, SE.SW, SW.SE);
public Quad W => Make(NW.SW, NW.SE, SW.NE, SW.NW);
And then I’ll make a static method that takes a Quad and returns the center stepped forward one tick. (Why not an instance method on Quad? We will see in a moment.)
private static Quad Step(Quad q)
{
Debug.Assert(q.Level >= 2);
Quad r;
if (q.IsEmpty)
r = Empty(q.Level - 1);
else if (q.Level == 2)
r = StepBaseCase(q);
else
{
Quad q9nw = Step(q.NW);
Quad q9n = Step(q.N);
Quad q9ne = Step(q.NE);
Quad q9w = Step(q.W);
Quad q9c = Step(q.Center);
Quad q9e = Step(q.E);
Quad q9sw = Step(q.SW);
Quad q9s = Step(q.S);
Quad q9se = Step(q.SE);
Quad q4nw = Make(q9nw, q9n, q9c, q9w);
Quad q4ne = Make(q9n, q9ne, q9e, q9c);
Quad q4se = Make(q9c, q9e, q9se, q9s);
Quad q4sw = Make(q9w, q9c, q9s, q9sw);
Quad rnw = q4nw.Center;
Quad rne = q4ne.Center;
Quad rse = q4se.Center;
Quad rsw = q4sw.Center;
r = Make(rnw, rne, rse, rsw);
}
Debug.Assert(q.Level == r.Level + 1);
return r;
}
Well that was easy! We just do nine recursions and then reorganize the resulting nine one-tick-forward quads until we get the information we want, and return it. (I added a little easy out for the empty case, though strictly speaking that is not necessary.)
There are probably three things on your mind right now.
- If we get a full quad-size smaller every time we step, we’re going to get down to a very small board very quickly!
- QuickLife memoized the step-the-center-of-a-2-quad operation. Why aren’t we doing the same thing here?
- Nine recursions is a lot; isn’t this going to blow up performance? Suppose we have an 8-quad; we do nine recursions on 7-quads, but each of those does nine recursions on 6-quads, and so on down to 3-quads. It looks like we are doing 9n-2 calls to the base case when stepping an n-quad forward one tick.
First things first.
When do we not care if we’re shrinking an n-quad down to an (n-1)-quad on step? When all living cells in the n-quad are already in the center (n-1)-quad. But that condition is easy to achieve! Let’s actually write our public step method, not just the helper that steps a quad. And heck, let’s make sure that we have more than enough empty space. Remember, empty space is super cheap.
sealed class Gosper : ILife, IDrawScale, IReport
{
private Quad cells;
private long generation;
...
public void Step()
{
Quad current = cells;
Make cells bigger until there are two “levels” of empty cells surrounding the center. (We showed Embiggen last time.) That way we are definitely not throwing away any living cells when we get a next state that is one size smaller:
if (!current.HasAllEmptyEdges)
current = current.Embiggen().Embiggen();
else if (!current.Center.HasAllEmptyEdges)
current = current.Embiggen();
Quad next = Step(current);
We’ve stepped, so next is one size smaller than current. Might as well make it bigger too; that’s one fewer thing to deal with next time. Again, empty space is cheap.
cells = next.Embiggen();
generation += 1;
}
HasAllEmptyEdges is an easy helper method of Quad:
public bool HasAllEmptyEdges =>
NW.NW.IsEmpty &&
NW.NE.IsEmpty &&
NE.NW.IsEmpty &&
NE.NE.IsEmpty &&
NE.SE.IsEmpty &&
SE.NE.IsEmpty &&
SE.SE.IsEmpty &&
SE.SW.IsEmpty &&
SW.SE.IsEmpty &&
SW.SW.IsEmpty &&
SW.NW.IsEmpty &&
NW.SW.IsEmpty;
That was an easy problem to knock down. Second problem: QuickLife memoized the 2-quad-to-1-quad step algorithm and got a big win; shouldn’t we do the same thing?
Sure, we have a memoizer, we can do so easily. But… what about our third problem? We have a recursive step that is creating exponentially more work as the quad gets larger as it traverses our deduplicated tree structure.
Hmm.
It is recursing on a deduplicated structure, which means it is probably going to encounter the same problems several times. If we move a 3-quad forward one step to get a 2-quad, we’re going to get the same answer the second time we do the same operation on the same 3-quad. If we move a 4-quad forward one step to get a 3-quad, we will get the same answer the second time we do it. And so on. Let’s just memoize everything.
We’ll rename Step to UnmemoizedStep, create a third memoizer, and replace Step with:
private static Quad Step(Quad q) =>
CacheManager.StepMemoizer.MemoizedFunc(q);
And now we have solved our second and third problems with one stroke.
Let’s run it! We’ll do our standard performance test of 5000 generations of acorn:
Algorithm time(ms) size Mcells/s
Naïve (Optimized): 4000 8 82
Abrash (Original) 550 8 596
Stafford 180 8 1820
QuickLife 65 20 ?
Gosper v1 3700 60 ?
Oof.
It’s slow! Not as slow as the original naïve implementation, but just about.
Hmm.
That’s the time performance; what’s the memory performance? There’s a saying I’ve used many times; I first heard it from Raymond Chen but I don’t know if he coined it or was quoting someone else. “A cache without an expiration policy is called a memory leak”. Memory leaks can cause speed problems as well as memory problems because they increase burden on the garbage collector, which can slow down the whole system. Also, dictionaries are in theory O(1) access — that is, access time is the same no matter how big the cache gets — but theory and practice are often different as the dictionaries get very large.
How much memory are we using in this thing? The “empty” memoizer never has more than 61 entries, so we can ignore it. I did some instrumentation of the “make” and “step” caches; after 5000 generations of acorn:
- the step and make caches both have millions of entries
- half the entries were never read at all, only written
- 97% of the entries were read fewer than twenty times
- the top twenty most-read entries account for 40% of the total reads
This validates our initial assumption that there is a huge amount of regularity; the “unusual” situations recur a couple dozen times tops, and we spend most of our time looking at the same configurations over and over again.
This all suggests that we could benefit from an expiration policy. There are two things to consider: what to throw away, and when to throw it away. First things first:
- An LRU cache seems plausible; that is, when you think it is time to take stuff out of the cache, take out some fraction of the stuff that has been Least Recently Used. However LRU caches involve making extra data structures to keep track of when something has been used; we do extra work on each step, and it seems like that might have a performance impact given how often these caches are hit.
- The easiest policy is: throw it all away! Those 20 entries that make up 40% of the hits will be very quickly added back to the cache.
Let’s try the latter because it’s simple. Now, we cannot just throw it all away because we must maintain the invariant that Make agrees with Empty; that is, when we call Make with four empty n-quads and when we call Empty(n+1) we must get the same object out. But if we throw away the “make” cache and then re-seed it with the contents of the “empty” cache — which is only 61 entries, that’s easy — then we maintain that invariant.
When to throw it away? What we definitely do not want to happen is end up in a situation where we are throwing away stuff too often. We can make a very simple dynamically-tuned cache with this policy:
- Set an initial cache size bound. 100K entries, 1M entries, whatever.
- Every thousand generations, check to see if we’ve exceeded the cache size bound. If not, we’re done.
- We’ve exceeded the bound. Throw away the caches, do a single step, and re-examine the cache size; this tells us the cache burden of doing one tick.
- The new cache size bound is the larger of the current bound and twice the one-tick burden. That way if necessary the size bound gradually gets larger so we do less frequent cache resetting.
The code is straightforward; at the start of Step:
bool resetMaxCache = false;
if ((generation & 0x3ff) == 0)
{
int cacheSize = CacheManager.MakeQuadMemoizer.Count +
CacheManager.StepMemoizer.Count;
if (cacheSize > maxCache)
{
resetMaxCache = true;
ResetCaches();
}
}
“ResetCaches” throws away the step cache and resets the make cache to agree with the empty cache; I won’t bother to show it. At the end of Step:
if (resetMaxCache)
{
int cacheSize = CacheManager.MakeQuadMemoizer.Count +
CacheManager.StepMemoizer.Count;
maxCache = Max(maxCache, cacheSize * 2);
}
All right, let’s run it again!
Algorithm time(ms) size Mcells/s
Naïve (Optimized): 4000 8 82
Abrash (Original) 550 8 596
Stafford 180 8 1820
QuickLife 65 20 ?
Gosper v2 4100 60 ?
It’s worse. Heck, it is worse than the naive algorithm!
Sure, the top twenty cache entries account for 40% of the hits, and sure, 97% of the entries are hit fewer than twenty times. But the statistic that is relevant here that I omitted is: the top many hundreds of cache entries account for 50% of the hits. We don’t have to rebuild just the top twenty items in the cache to start getting a win from caching again. We take a small but relevant penalty every time we rebuild the caches.
Sigh.
We could keep on trying to improve the marginal performance by improving our mechanisms. We could try an LRU cache, or optimize the caches for reading those top twenty entries, or whatever. We might eke out some wins. But maybe instead we should take a step back and ask if there’s an algorithmic optimization that we missed.
Next time on FAIC: There is an algorithmic optimization that we missed. Can you spot it?