
Last time we implemented what looked like Gosper’s algorithm and got a disappointing result; though the quadtree data structure is elegant and the recursive algorithm is simple, and even though we memoize every operation, the time performance is on par with our original naive implementation, and the amount of space consumed by the memoizers is ginormous. But as I said last time, I missed a trick in my description of the algorithm, and that trick is the key to the whole thing. (Code for this episode is here.)
One reader pointed out that we could be doing a better job with the caching. Sure, that is absolutely true. There are lots of ways we could come up with a better cache mechanism than my hastily-constructed dictionary, and those would in fact lead to marginal performance gains. But I was looking for a win in the algorithm itself, not in the details of the cache.
A few readers made the astute observation that the number of recursions — nine — was higher than necessary. The algorithm I gave was:
- We are given an n-quad and wish to step the center (n-1)-quad.
- We make nine unstepped (n-1)-quads and step each of them to get nine stepped (n-2)-quads
- We reform those nine (n-2)-quads into four stepped (n-1)-quads, take the centers of each, and that’s our stepped (n-1) quad.
But we have all the information we need in the original n-quad to extract four unstepped (n-1)-quads. We then could step each of those to get four center stepped (n-2)-quads, and we can reform those into the desired (n-1)-quad.
Extracting those four unstepped (n-1)-quads is a fair amount of work, but there is an argument to be made that it might be worth the extra work in order to go from nine recursions to four. I didn’t try it, but a reader did and reports back that it turns out this is not a performance win. Regardless though, this wasn’t the win I was looking for.
Let’s go through the derivation one more time, and derive Gosper’s algorithm for real.
We still have our base case: we can take any 2-quad and get the center 1-quad stepped one tick forward. Suppose once again we are trying to step the outer green 3-quad forward; we step each of its component green 2-quads forward one tick to get these four blue 1-quads:
 We then extract the north, south, east, west and center 2-quads from the 3-quad and step each of those forwards one tick, and that gives us these nine blue 1-quads, each one step in the future:
We then extract the north, south, east, west and center 2-quads from the 3-quad and step each of those forwards one tick, and that gives us these nine blue 1-quads, each one step in the future:

We then form four 2-quads from those nine 1-quads; here we are looking at the northwest 2-quad and its center 1-quad:

The light blue 2-quad and its dark blue 1-quad center are both one tick ahead of the outer green 3-quad. This is where we missed our trick.
We have the light blue 2-quad, and it is one tick ahead of the green 3-quad. We want to get its center 1-quad. What if we got its center 1-quad stepped one tick ahead? We know we can do it! It’s a 2-quad and we can get the center 1-quad of any 2-quad stepped one tick ahead. We can make the innermost dark blue quad stepped two ticks ahead. We repeat that operation four times and we have enough information to construct…
 …the center 2-quad stepped two ticks ahead, not one.
…the center 2-quad stepped two ticks ahead, not one.
Now let’s do the same reasoning for a 4-quad.
We step its nine component 3-quads forwards two ticks, because as we just saw, we can do that for a 3-quad. We then compose those nine 2-quads into four 3-quads, step each of those forward two ticks, again because we can, and construct the center 3-quad stepped four ticks ahead.
And now let’s do the same reasoning for an n-quad… you see where this is going I’m sure.
This is the astonishing power of Gosper’s algorithm. Given an n-quad, we can step forward its center (n-1)-quad by 2n-2 ticks for any n>=2.
Want to know the state of the board a million ticks in the future? Embiggen the board until it is a 22-quad — we know that operation is cheap and easy — and you can get the center 21-quad stepped forwards by 220 ticks using this algorithm. A billion ticks? Embiggen it to a 32-quad, step it forward 230 ticks.
We showed last time an algorithm for stepping an n-quad forward by one tick; here we’ve sketched an algorithm for stepping an n-quad forward by 2n-2 ticks. What would be really nice from a user-interface perspective is if we had a hybrid algorithm that can step an n-quad forward by 2k ticks for any k between 0 and n-2.
You may recall that many episodes ago I added an exponential “speed factor” where the factor is the log2 of the number of ticks to step. We can now write an implementation of Gosper’s algorithm for real this time that takes a speed factor. Rather than try to explain it further, let’s just look at the code.
private static Quad UnmemoizedStep((Quad q, int speed) args)
{
Quad q = args.q;
int speed = args.speed;
Debug.Assert(q.Level >= 2);
Debug.Assert(speed >= 0);
Debug.Assert(speed <= q.Level - 2);
Quad r;
if (q.IsEmpty)
r = Quad.Empty(q.Level - 1);
else if (speed == 0 && q.Level == 2)
r = StepBaseCase(q);
else
{
// The recursion requires that the new speed be not
// greater than the new level minus two. Decrease speed
// only if necessary.
int nineSpeed = (speed == q.Level - 2) ? speed - 1 : speed;
Quad q9nw = Step(q.NW, nineSpeed);
Quad q9n = Step(q.N, nineSpeed);
Quad q9ne = Step(q.NE, nineSpeed);
Quad q9w = Step(q.W, nineSpeed);
Quad q9c = Step(q.Center, nineSpeed);
Quad q9e = Step(q.E, nineSpeed);
Quad q9sw = Step(q.SW, nineSpeed);
Quad q9s = Step(q.S, nineSpeed);
Quad q9se = Step(q.SE, nineSpeed);
Quad q4nw = Make(q9nw, q9n, q9c, q9w);
Quad q4ne = Make(q9n, q9ne, q9e, q9c);
Quad q4se = Make(q9c, q9e, q9se, q9s);
Quad q4sw = Make(q9w, q9c, q9s, q9sw);
// If we are asked to step forwards at speed (level - 2),
// then we know that the four quads we just made are stepped
// forwards at (level - 3). If we step each of those forwards at
// (level - 3) also, then we have the center stepped forward at
// (level - 2), as desired.
//
// If we are asked to step forwards at less than speed (level - 2)
// then we know the four quads we just made are already stepped
// that amount, so just take their centers.
if (speed == q.Level - 2)
{
Quad rnw = Step(q4nw, speed - 1);
Quad rne = Step(q4ne, speed - 1);
Quad rse = Step(q4se, speed - 1);
Quad rsw = Step(q4sw, speed - 1);
r = Make(rnw, rne, rse, rsw);
}
else
{
Quad rnw = q4nw.Center;
Quad rne = q4ne.Center;
Quad rse = q4se.Center;
Quad rsw = q4sw.Center;
r = Make(rnw, rne, rse, rsw);
}
}
Debug.Assert(q.Level == r.Level + 1);
return r;
}
As I’m sure you’ve guessed, yes, we’re going to memoize this too! This power has not come for free; we are now doing worst case 13 recursions per non-base call, which means that we could be doing worst case 13n-3 base case calls in order to step forwards 2n-2 ticks, and that’s a lot of base case calls. How on earth is this ever going to work?
Again, because (1) we are automatically skipping empty space of every size; if we have an empty 10-quad that we’re trying to step forwards 256 ticks, we immediately return an empty 9-quad, and (2) thanks to memoization every time we encounter a problem we’ve encountered before, we just hand back the solution. The nature of Life is that you frequently encounter portions of boards that you’ve seen before because most of a board is stable most of the time. We hope.
That’s the core of Gosper’s algorithm, finally. (Sorry it took 35 episodes to get there, but it was a fun journey!) Let’s now integrate that into our existing infrastructure; I’ll omit the memoization and cache management because it’s pretty much the same as we’ve seen already.
The first thing to note is that we can finally get rid of this little loop:
public void Step(int speed)
{
for (int i = 0; i < 1L << speed; i += 1)
Step();
}
Rather than implementing Step(speed) in terms of Step(), we’ll go the other way:
public void Step()
{
Step(0);
}
public void Step(int speed)
{
// Cache management omitted
const int MaxSpeed = MaxLevel - 2;
Debug.Assert(speed >= 0);
Debug.Assert(speed <= MaxSpeed);
The embiggening logic needs to be a little more aggressive. This implementation is probably more aggressive than we need it to be, but remember, empty space is essentially free both in space and processing time.
Quad current = cells;
if (!current.HasAllEmptyEdges)
current = current.Embiggen().Embiggen();
else if (!current.Center.HasAllEmptyEdges)
current = current.Embiggen();
while (current.Level < speed + 2)
current = current.Embiggen();
Quad next = Step(current, speed);
cells = next.Embiggen();
generation += 1L << speed;
// Cache reset logic omitted
}
Now how are we going to perf test this thing? We already know that calculating 5000 individual generations of “acorn” with Gosper’s algorithm will be as slow as the original naïve version. What happens if for our performance test we set up acorn and then call Step(13)? That will step it forwards 8196 ticks:
Algorithm time(ms) size Mcells/s Naïve (Optimized): 4000 8 82 Abrash (Original) 550 8 596 Stafford 180 8 1820 QuickLife 65 20 ? Gosper, sp 0 * 5000 3700 60 ? Gosper, sp 13 * 1 820 60 ?
Better, but still not as good as any of our improvements over the naïve algorithm, and 13x slower than QuickLife.
So this is all very interesting, but what’s the big deal?
Do you remember the asymptotic time performance of Hensel’s QuickLife? It was O(changes); that is, the cost of computing one tick forwards is proportional to the number of changed cells on that tick. Moreover, period-two oscillators were essentially seen as not changing, which is a huge win.
We know that the long-term behaviour of acorn is that shortly after 5000 ticks in, we have only a handful of gliders going off to infinity and all the rest of the living cells are either still Lifes or period-two oscillators that from QuickLife’s perspective, might as well be still Lifes. So in the long run, the only changes that QuickLife has to process are the few dozens of cells changed for each glider; everything else gets moved into the “stable” bucket.
Since in the long run QuickLife is processing the same number of changes per tick, we would expect that the total time taken to run n ticks of acorn with QuickLife should grow linearly. Let’s actually try it out to make sure. I’m going to run one ticks of acorn with QuickLife, then reset, then run two ticks , then reset, then run four ticks, reset, eight ticks, and so on, measuring the time for each, up to 221 =~ 2.1 million ticks.
Here is a graph of the results; milliseconds on the y axis, ticks on the x axis, log-log scale. Lower is faster.
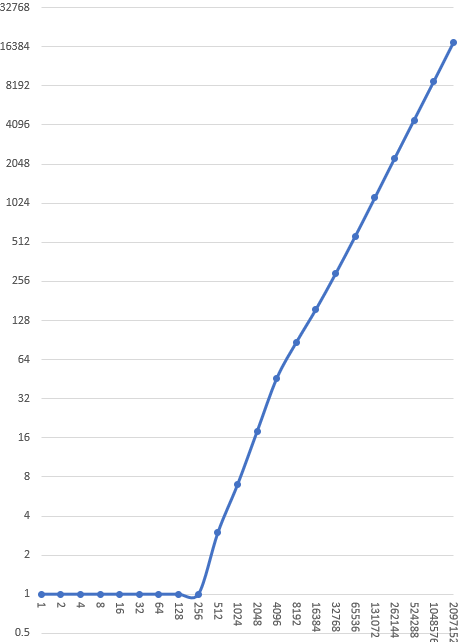 Obviously the leftmost portion of the graph is wrong; anything less than 256 ticks takes less than 1 millisecond but I haven’t instrumented my implementation to measure sub-millisecond timings because I don’t care about those. I’ve just marked all of them as taking one millisecond.
Obviously the leftmost portion of the graph is wrong; anything less than 256 ticks takes less than 1 millisecond but I haven’t instrumented my implementation to measure sub-millisecond timings because I don’t care about those. I’ve just marked all of them as taking one millisecond.
Once we’re over a millisecond, you can see that QuickLife’s time to compute some number of ticks grows linearly; it’s about 8 microseconds per tick, which is pretty good. You can also see that the line changes slope slightly once we get to the point where it is only the gliders on the active list; the slope gets shallower, indicating that we’re taking less time for each tick.
Now let’s do the same with Gosper’s algorithm; of course we will make sure to reset the caches between every run! Otherwise we would be unfairly crediting speed improvements in later runs to cached work that was done in earlier runs.
Hensel’s QuickLife in blue, Gosper’s HashLife in orange:

Holy goodness!
The left hand side of the graph shows that Gosper’s algorithm is consistently around 16x slower than QuickLife in the “chaos” part of acorn’s evolution, right up to the point where we end up in the “steady state” of just still Lifes, period-two oscillators and gliders. The right hand side of the graph shows that once we are past that point, Gosper’s algorithm becomes O(1), not O(changes).
In fact this trend continues. We can compute a million, a billion, a trillion, a quadrillion ticks of acorn in around 800ms. And we can embiggen the board to accurately track the positions of those gliders even when they are a quadrillion cells away from the center.
What is the takeaway here? The whole point of this series is: you can take advantage of characteristics of your problem space to drive performance improvements. But what we’ve just dramatically seen here is that this maxim is not sufficient. You’ve also got to think about specific problems that you are solving.
Let’s compare and contrast. Hensel’s QuickLife algorithm excels when:
- All cells of interest fit into a 20-quad
- There is a relatively small number of living cells (because memory burden grows as O(living)
- You are making a small number of steps at a time
- Living cells are mostly still Lifes or period-two oscillators; the number of “active” Quad4s is relatively small
Gosper’s HashLife algorithm excels when:
- Boards must be of unlimited size
- Regularity in space — whether empty space or not — allows large regions to be deduplicated
- You are making a large number of steps at a time
- Regularity in time allows for big wins by caching and re-using steps we’ve seen already.
- You’ve got a lot of memory! Because the caches are going to get big no matter what you do.
That’s why Gosper’s algorithm is so slow if you run in on the first few thousand generations of acorn; that evolution is very chaotic and so there are a lot of novel computations to do and comparatively less re-use. Once we’re past the chaotic period, things become very regular in both time and space, and we transition to a constant-time performance.
That is the last algorithm I’m going to present but I have one more thing to discuss in this series.
Next time on FAIC: we will finally answer the question I have been teasing all this time: are there patterns that grow quadratically? And how might our two best algorithms handle such scenarios?

Pingback: The Morning Brew - Chris Alcock » The Morning Brew #3069
Your final content paragraph (“That’s why Gosper’s …”) contains the seeds of a fascinating dichotomy. Acorn has the property that its behavior is chaotic for awhile (~5K steps) then fairly abruptly becomes highly stereotypical when it converts to a squadron of gliders. The pattern’s evolution consists of two very different phases with wildly different behaviors and hence wildly different most efficient algorithms.
If many / most / all Life starting arrangements have a similar 2-phase evolution then Gosper will win once we get far enough out into the second phase to make up for Gosper’s gross underperformance in the early phase . But if the phase change point is at a few million iterations then the point where Gosper surpasses QuickLife will be way, way out there. Perhaps farther than we can stand to wait for.
And what of patterns that don’t have this biphasic behavior? Do such exist that remain chaotic forever? Or that oscillate between regular and chaotic phases? Of all possible starting patterns in, say, an 8-quad (32k x 32K cells), how many of the “interesting” ones are “Gosper-compatible”?
Not that I expect you to have answers to these questions, but they’re interesting in their own right as to Life and, more importantly, bear directly on your overall pedagogic objective to talk about algorithm design informed by the nature of the problem to be solved. In this case we may almost care more about the “meta-nature” of the problem, i.e. it’s phasic (or not) nature, rather than the lower-level “obvious” nature of how individual cells and groups of cells evolve over some range of ticks.
In non-trivial software solving non-trivial exploratory problems the meta-nature (and meta-meta-nature?) may be the real drivers for design and for performance. Most especially at serious scale, with which so much of modern computing is concerned. In a sound bite: “How to know the meta-nature? Aye, there’s the rub!”
I’d love to learn more about exactly what conditions are required to achieve this O(1) characteristic. Does every Life pattern hold it? My intuition is that space-fillers will, since they are basically tri-phasic in space: empty, border, and filled.
I’m also interested in the memory characteristics of these two algorithms. What’s the asymptotic memory performance of HashLife/QuickLife?