We now have enough gear to make a naïve “proto-QuickLife” implementation as a test to see (1) does it work at all? and (2) what is the performance compared to our other implementations at various levels of sophistication?
Code for this episode is here.
So far I’ve given you code for Quad2, Quad3, Quad4, the stepping algorithm for a Quad4 on even and odd cycles, and a lookup table to step even and odd Quad2s, so I won’t repeat that. What we need now is code to hold the whole thing together. I’ll omit a bunch of the code that does not relate directly to the task at hand, such as how we draw the screen, how we handle creating the initial pattern, and so on; see the source code link above if those algorithms interest you.
sealed class ProtoQuickLife : ILife, IReport
{
// Number of 4-quads on a side.
private const int size = 16;
private int generation;
private Dictionary<(short, short), Quad4> quad4s;
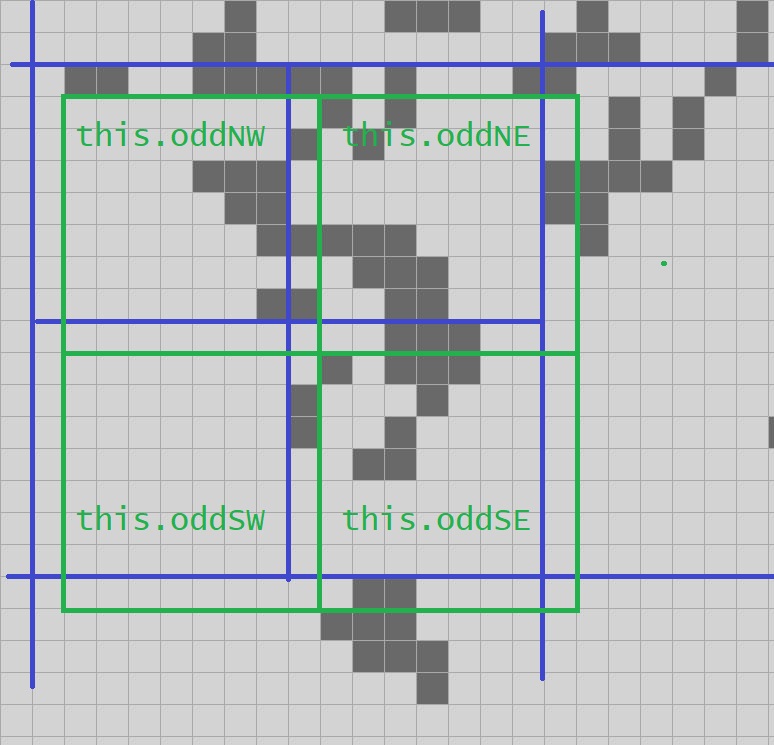
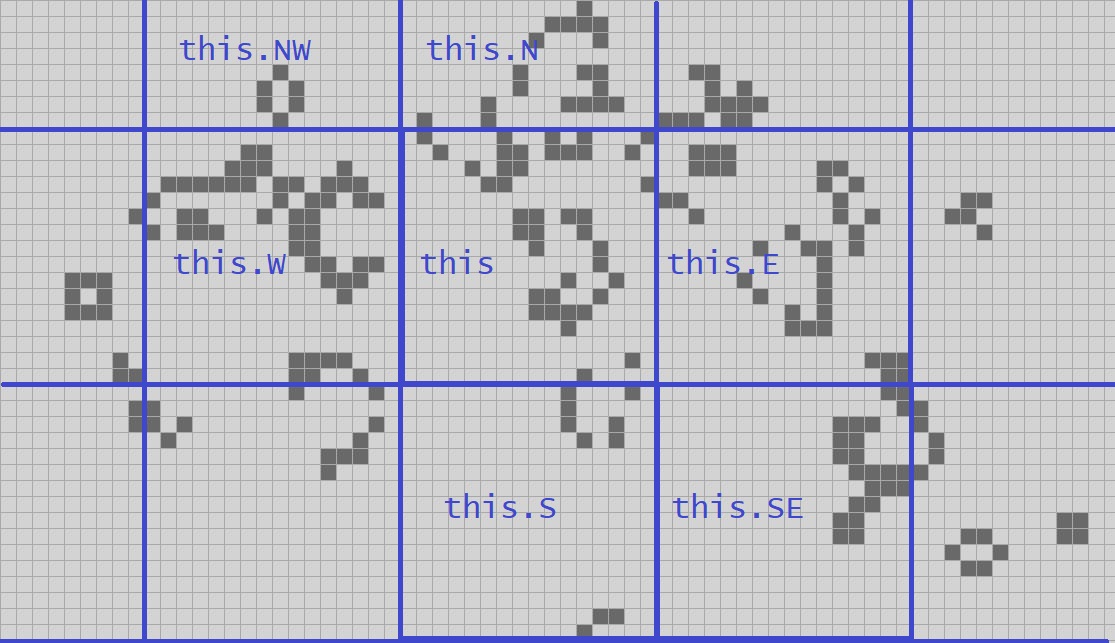
For our proto-QuickLife I’m just going to go with the same thing we saw in all of our previous fixed-size implementations: I’ll make an 8-quad. We have a 4-quad data structure in hand, and so we’ll need a 16 x 16 grid of 4-quads.
We need to know whether we are on an odd or even generation, so I’ve made a generation counter.
Since we have a fixed-size grid in this prototype version, I could just have an array of 256 Quad4s. However, in later versions of this algorithm we are going to use the sparse array technique I discussed in a previous episode, but it will be a sparse array of Quad4s, not cells! We’ll index our sparse array by a pair of shorts; that gives us a sparse 20-quad to play with, which is plenty of space; that’s a square with just over a million cells on a side. We might as well write the code for the sparse array now, and save having to write it again later.
public void Clear()
{
generation = 0;
quad4s = new Dictionary<(short, short), Quad4>();
for (int y = 0; y < size; y += 1)
for (int x = 0; x < size; x += 1)
AllocateQuad4(x, y);
}
Some easy initialization code that allocates 256 Quad4s and puts them in a sparse array. A Quad4, recall, has six references to neighbouring Quad4s and everything else is a struct, so we will need to initialize those references; the structs will have their default values which, fortunately, is “all dead”.
private Quad4 AllocateQuad4(int x, int y)
{
Quad4 c = new Quad4(x, y);
c.S = GetQuad4(x, y - 1);
if (c.S != null)
c.S.N = c;
... and so on for N, E, W, SE, NW ...
SetQuad4(x, y, c);
return c;
}
private Quad4 GetQuad4(int x, int y)
{
quad4s.TryGetValue(((short)x, (short)y), out var q);
return q;
}
private void SetQuad4(int x, int y, Quad4 q) =>
quad4s[((short)x, (short)y)] = q;
On all code paths to these private methods we will already know that the x, y coordinates are in bounds, so we have no problem casting them to shorts. I suppose there is some possibility that on the edges we will have “wrap around” behaviour for the additions and subtractions, but I’m not going to worry about it for the purposes of this blog.
And finally, the mainspring that drives the whole thing:
private bool IsOdd => (generation & 0x1) != 0;
public void Step()
{
if (IsOdd)
StepOdd();
else
StepEven();
generation += 1;
}
private void StepEven()
{
foreach (Quad4 q in quad4s.Values)
q.StepEven();
}
private void StepOdd()
{
foreach (Quad4 q in quad4s.Values)
q.StepOdd();
}
Well that was all easy — as it should be, since the complicated work right now is in Quad4. (Don’t worry; this class will get much more complicated in coming episodes as we add optimizations.)
What do you think the time performance of this initial prototype is? Remember, this is a fully naïve implementation in the sense that we are not doing any kind of change tracking, we are not identifying “all dead” Quad4s and skipping them, and so on. We have a 256×256 grid and we are computing the next generation by looking at every one of those cells; the optimization we have with our lookup table is that we compute the results “four at a time” via lookup to get a 1-quad rather than by counting neighbours.
To get an apples-to-apples comparison I ran the proto-QuickLife algorithm using the same test as we’ve done so far in this series: 5000 ticks of “acorn” on an 8-quad. Make a guess, and then scroll down for the results.
.
.
.
.
.
.
Algorithm time(ms) ticks size(quad) megacells/s Naïve (Optimized): 4000 5K 8 82 Abrash (Original) 550 5K 8 596 Stafford 180 5K 8 1820 Proto-QuickLife 770 5K 8 426
A considerable improvement over the original naïve algorithm, but unsurprisingly, not as fast as our more optimized solutions.
What about memory? In this prototype implementation we have 65536 cells, and we are storing two generations. How many bits are we using? (We will ignore fixed costs such as the lookup tables.) If we suppose that references are 8 bytes then:
- A Quad2 is exactly 2 bytes
- A Quad3 is exactly 8 bytes
- A Quad4 has eight Quad3s, so 64 bytes for the data, plus 4 bytes for the coordinates, plus 48 bytes for the references, plus another 4 bytes for the object header maintained by the runtime. That’s 120 bytes per Quad4. Oh, and our sparse array has an overhead of at minimum 12 bytes per entry, since an entry is two shorts and a reference, so call it 132 bytes all up.
- We’ve got 256 Quad4s in this implementation, so that’s 33792 bytes to represent 65536 cells, or just slightly over four bits per cell.
That’s not bad; recall that Stafford’s algorithm was 5 bits per cell.
We are off to a good start here.
Coming up on FAIC:
We’ve created a solid foundation for adding more optimizations and features. In the next few episodes we will explore these questions:
- As we have seen several times already in this series, if we identify what cells are changing then we can spend time on only those cells. Can we use the fact that we are storing two generations worth of cells in each Quad4 to make an even better change-tracking optimization?
- Even if we eliminate the time cost, an all-dead Quad4 with all-dead neighbours seems like it is taking up space unnecessarily. Can we efficiently prune all-dead Quad4s from the sparse array and save on that space?
- If we have robust change tracking then we can discover changing cells that border a “missing” Quad4. Can we grow the set of Quad4s dynamically as a pattern expands into new space, and thereby achieve Life on an 20-quad?