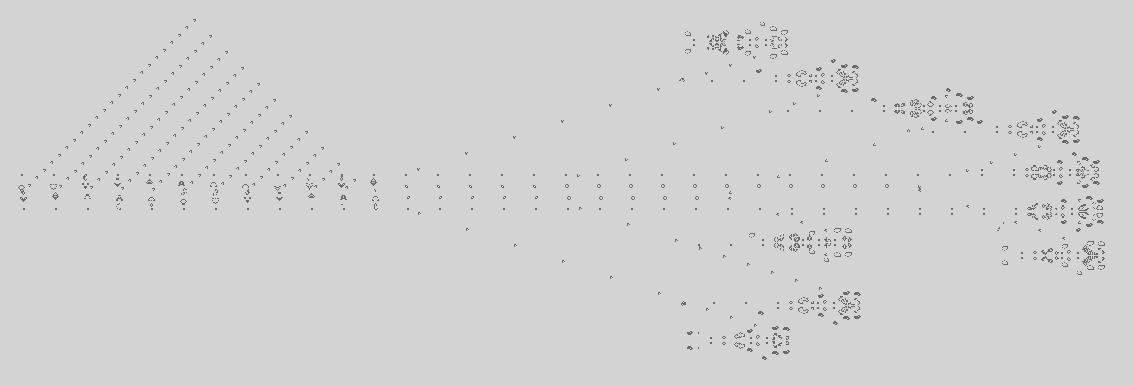
Earlier this week I was looking for an old photo, and while browsing I came across a photo I took of my whiteboard in my office at Microsoft in 2004. Or rather, it was two photos; I’ve crudely stitched them together. Click on the image for a larger version.

OMG. What. The. Heck. Is. All. That. Nonsense?
Let me start with a little history.
Before I was on the C# team and after I was on the scripting languages team, I spent a couple years at Microsoft working on the plumbing for Visual Studio Tools for Office.
The idea of VSTO was to bring the ability to write truly rich, client-server aware, data-driven applications in Office documents using C# or Visual Basic; we wanted to go beyond the scripts and productivity tools typical of VBA customizations.
This was a project with many, many difficulties, both technical and political. On the political side of things, I think it is fair to say that the Office team has historically had (with good reason!) a great deal of resistance to taking any compatibility burden that would possibly slow down their ability to innovate in future releases; “platformizing” Word and Excel into true application hosts by a team external to Office was just such a burden.
The technical difficulties were considerable, in large part due to concerns about the security model. We were deeply, painfully aware of how Office customizations and scripting languages had been misused in the past as vectors for malware, and we did not want to create new vulnerabilities. As mitigation, we designed a mechanism that would isolate any customization code to its own appdomain with a highly restrictive default security policy.
Office, however, was not at the time designed to host the CLR. They were only willing to give us a single callback to our loader code that kicked off the whole process when a customized spreadsheet or document was loaded.
By 2004 we were on the fourth revision to our loading algorithm and I was tasked with coming up with the fifth; to facilitate discussion of options I drew a diagram on my whiteboards which I helpfully titled “HIGHLY SIMPLIFIED STARTUP SEQUENCE v4”.
A few things strike me about this diagram now, over 16 years later.
First: though it looks like a mess, I did actually put some thought into the design elements.
- The diagram is divided into three sections, separated by heavy blue vertical lines. On the left are components running entirely outside of the CLR; in the middle are components that run in the CLR’s default appdomain, and on the right are components that run in the customization’s restricted appdomain. (And of course on the extreme far left is the edge of my “THE MATRIX” poster. A lot of the code names of the different parts of the project were references to The Matrix, including the team cover band that I played keyboards for. I am sad that I can no longer wear my “The Red Pills” polo shirt in public due to the co-opting of that movie reference by misogynist jerks.)
- The purple boxes that run along the top are components and the lollipops give the interfaces they implement.
- The purple boxes and arrows below give the exact sequence of twenty different method calls showing what component is calling what other component with what data, and why. In particular the diagram allows us to easily see when a component running in a more restricted security environment is calling into a less restricted environment; those calls need to be allowed because we need them to happen, but that then means that maybe hostile user code could call them, which could be bad.
- Design problems, questions, annotations and proposed changes are shown in blue.
- Red is used to identify one key component and an important question about it.
- I have no idea what that yellow code fragment is or why it was written over top of everything else. It looks irrelevant.
The purpose of the diagram was originally to clarify in my own mind what the sequence was and what the problems were, but by the time it was in this form it was also for giving context to my coworkers when we were discussing options, so it had to be readable. I probably redrew this diagram a half a dozen times before it got to this state.
Second: we can see that there were a good half dozen or more design problems that I was trying to solve here but the big problems involved dirty documents and application manifests.
When you close Word or Excel, you have I am sure noticed that sometimes you get a “save your work?” dialog and sometimes the app just closes. The app is keeping track of whether the document is dirty — changed since it was last loaded or saved — or clean.
Suppose we load a customized spreadsheet, and initializing the customization causes the installer to notice that there is a newer version that it should be downloading. That might change the manifest information about the customization, so the spreadsheet is now “dirty”. But we do not want to ever unnecessarily dirty a document, because that is confusing and irritating to the user.
In step nine the fake application activator obtains an IAppInfo reference from the appdomain manager, updates the manifest from the customization’s server, and parses the manifest. My comments say:
- Do not write back at this point; need to maintain dirty state
- No, don’t do this at all. Host must provide updated manifest. This is not a VSTA feature, it is VSTO. (Meaning here that something here is unique to Visual Studio Tools for Office, and not the generalization of it we were working on, VST for Applications.)
- Must do both. Don’t write back. AIState object must ensure dirtyness.
Apparently I was deeply conflicted on this point. I don’t recall how it was resolved.
My favourite comment though is the one in red:
Can we take manifest out of doc? Peter: “It would be awesome. If assembly is available offline, so is manifest”.
The scenario here had something to do with both the dirty bit problem, and more generally dealing with locally cached customizations. We did a bunch of work on the security model for “what happens if you’re trying to run a customization while your laptop is in airplane mode and we can’t get to the server to check for updates”. Peter is of course legendary Microsoft PM Peter Torr with whom I worked for many years.
My second favourite was where I said “OFFICE12?” Yeah, what’s going to happen when Office revs? Can we guarantee that all this stuff keeps working?
Third: It’s funny how the mind works. Though I’ve described the organization of the diagram and the major problems, today I remember almost none of what is going on here, what the specific issues were, or how we resolved them. But that whole sequence was intensely important to me for several months of my life; it was the foundational plumbing to the entire endeavor and so I knew it literally forwards and backwards. Those memories are 90% gone now. And yet if someone were to yell the numbers “nine six seven eleven eleven” at me from across the street I would be unable to not think “call Pizza Pizza, right away“. Thanks, 1980s jingle writers.
Fourth: I often think about this sort of thing in the context of those “tell me about a time you solved a design problem” interview questions. This “highly simplified” startup sequence with its twenty method calls has to balance:
- security
- performance
- privacy
- debuggability
- code maintainability
- versioning
- robustness
- graceful failure
- user irritation
and numerous other design criteria. But can you imagine trying to explain any detail of this diagram to someone with no prior knowledge in a 45 minute interview? Real-world design problems are hard precisely because there are so many conflicting goals and messy politics. And worse, too often this is the institutional knowledge that is never written down and then lost.
Coming up on FAIC: Not sure!
- I want to embark upon a more detailed dive into Bean Machine
- We have just open-sourced a tool we use for benchmarking PPLs internally; I’d like to talk about that a bit
- I’ve developed a little AST rewriting library in Python that is kinda fun; I could delve into the ideas behind that.
Let me know in the comments what you think.