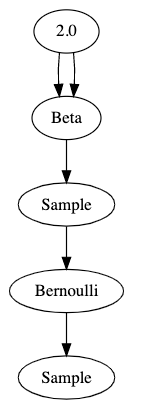
Let’s take another look at the “hello world” example and think more carefully about what is actually going on:
@random_variable
def fairness():
return Beta(2,2)
@random_variable
def flip(n):
return Bernoulli(fairness())
heads = tensor(1)
tails = tensor(0)
observations = { flip(0) : heads, ... flip(9): tails }
queries = [ fairness() ]
num_samples = 10000
results = BMGInference().infer(queries, observations, num_samples)
samples = results[fairness()]
There’s a lot going on here. Let’s start by clearing up what the returned values of the random variables are.
It sure looks like fairness() returns an instance of a pytorch object — Beta(2,2) — but the model behaves as though it returned a sample from that distribution in the call to Bernoulli. What’s going on?
The call doesn’t return either. It returns a random variable identifier, which I will abbreviate as RVID. An RVID is essentially a tuple of the original function and all the arguments. (If you think that sounds like a key to a memoization dictionary, you’re right!)
This is an oversimplification, but you can imagine for now that it works like this:
def random_variable(original_function):
def new_function(*args):
return RVID(original_function, args)
# The actual implementation stashes away useful information
# and has logic needed for other Bean Machine inference algorithms
# but for our purposes, pretend it just returns an RVID.
return new_function
def fairness():
return Beta(2,2)
fairness = random_variable(fairness)
The decorator lets us manipulate function calls which represent random variables as values! Now it should be clear how
queries = [ fairness() ]
works; what we’re really doing here is
queries = [ RVID(fairness, ()) ]
That clears up how it is that we treat calls to random variables as unique values. What about inference?
Leaving aside the behavior of the decorators to cause random variables to generate RVIDs, our “hello world” program acts just like any other Python program right up to here:
results = BMGInference().infer(queries, observations, num_samples)
Argument queries is a list of RVIDs, and observations is a dictionary mapping RVIDs onto their observed values. Plainly infer causes a miracle to happen: it returns a dictionary mapping each queried RVID onto a tensor of num_samples values that are plausible samples from the distribution of the posterior of the random variable.
Of course it is no miracle. We do the following steps:
- Transform the source code of each queried or observed function (and transitively their callees) into an equivalent program which partially evaluates the model, accumulating a graph as it goes
- Execute the transformed code to accumulate the graph
- Transform the accumulated graph into a valid BMG graph
- Perform inference on the graph in BMG
- Marshal the samples returned into the dictionary data structure expected by the user
Coming up on FAIC: we will look at how we implemented each of those steps.