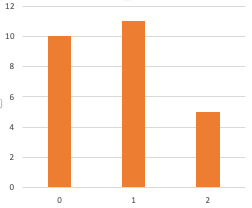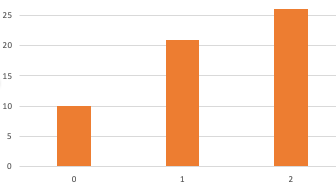Last time on FAIC we discovered the interesting fact that conditional probabilities can be represented as likelihood functions, and that applying a conditional probability to a prior probability looks suspiciously like SelectMany, which is usually the bind operation on the sequence monad. We created a new implementation of SelectManythat creates an object which samples from the prior, calls the likelihood, and then samples from the resulting distribution. Is that the bind operation on the probability distribution monad?
Aside: If you’re completely confused by the preceding paragraph, you might want to read my gentle introduction to monads for OO programmers. Go ahead and read that over if it is not fresh in your mind.
We need the following things to have a monad in C#:
- We need an “embarrassingly generic” type: some
Foo<T>where it can sensibly take on anyTwhatsoever.IDiscreteDistribution<T>meets that condition. - The type represents an “amplification of power” of the underlying type. Indeed it does; it allows us to represent a probability distribution of particular values of that type, which is certainly a new power that we did not have before.
- We need a way of taking any specific value of any
T, and creating an instance of the monadic type that represents that specific value.Singleton.Distribution(t)meets that condition. - There is frequently(but not necessarily) an operation that extracts a value of the underlying type from an instance of the monad.
Sample()is that operation. Note that sampling a singleton always gives you back the original value. - There is a way to “bind” a new function onto an existing instance of the monad. That operation has the signature
M<R> SelectMany<A, R>(M<A> m, Func<A, M<R>> f). We traditionally call itSelectManyin C# because that’s the bind operation onIEnumerable<T>, and it produces a projection on all the elements from a sequence of sequences. As we saw last time, we have this function for probability distributions. - Binding the “create a new instance” function to an existing monad must produce an equivalent monad. I think it is pretty clear that if we have an
IDiscreteDistributionin hand, call itd, thatSelectMany(d, t => Singleton.Distribution(t))produces an object that has the same distribution thatddoes. If that’s not clear, play around with the code until it becomes clear to you. - Going “the other direction” must also work. That is, if we have a
Func<A, IDiscreteDistribution<B>>calledf, and a value ofA, thenSelectMany(Singleton<A>.Distribution(a), f)andf(a)must produce logically the sameIDiscreteDistribution<B>. Again, if that’s not clearly true in your mind, step through the code mentally or write some sample code and convince yourself that it is true. - Two bind operations “on top of each other” must produce the same logical result as a single bind that is the composition of the two bound functions. That’s maybe a little vague; see Part 7 of my series on monads for details. Suffice to say, we meet this condition as well.
All our conditions are met; IDiscreteDistribution<T> is a monad. So we should be able to use it in a query comprehension, right?
from c in cold
from s in SneezedGivenCold(c)
select s
Unfortunately this gives an error saying that SelectMany cannot be found; what’s up with that?
The query comprehension syntax actually requires a slight variation on the traditional “bind” operation; it requires that we also allow a projection on the end, and that moreover, the projection take both the original value and the transformed value. That is, C# requires us to implement it like this:
public sealed class Combined<A, B, C> :
IDiscreteDistribution<C>
{
private readonly List<C> support;
private readonly IDiscreteDistribution<A> prior;
private readonly Func<A, IDiscreteDistribution<B>> likelihood;
private readonly Func<A, B, C> projection;
public static IDiscreteDistribution<C> Distribution(
IDiscreteDistribution<A> prior,
Func<A, IDiscreteDistribution<B>> likelihood,
Func<A, B, C> projection) =>
new Combined<A, B, C>(prior, likelihood, projection);
private Combined(
IDiscreteDistribution<A> prior,
Func<A, IDiscreteDistribution<B>> likelihood,
Func<A, B, C> projection)
{
this.prior = prior;
this.likelihood = likelihood;
this.projection = projection;
var s = from a in prior.Support()
from b in this.likelihood(a).Support()
select projection(a, b);
this.support = s.Distinct().ToList();
}
public IEnumerable<C> Support() =>
this.support.Select(x => x);
public int Weight(C c) => NOT YET!
public C Sample()
{
A a = this.prior.Sample();
B b = this.likelihood(a).Sample();
return this.projection(a, b);
}
}
And now we can implement SelectMany as
public static IDiscreteDistribution<C> SelectMany<A, B, C>(
this IDiscreteDistribution<A> prior,
Func<A, IDiscreteDistribution<B>> likelihood,
Func<A, B, C> projection) =>
Combined<A, B, C>.Distribution(prior, likelihood, projection);
and of course if we want a SelectMany with the traditional monad bind signature, that’s just
public static IDiscreteDistribution<B> SelectMany<A, B>(
this IDiscreteDistribution<A> prior,
Func<A, IDiscreteDistribution<B>> likelihood) =>
SelectMany(prior, likelihood, (a, b) => b);
Now that we have aSelectMany, we can write conditional probabilities in comprehension syntax, as before:
var sneezed = from c in cold
from s in SneezedGivenCold(c)
select s;
or, if we like, we can extract a tuple giving us both values:
public static IDiscreteDistribution<(A, B)> Joint<A, B>(
this IDiscreteDistribution<A> prior,
Func<A, IDiscreteDistribution<B>> likelihood) =>
SelectMany(prior, likelihood, (a, b) => (a, b));
var joint = cold.Joint(SneezedGivenCold);
and if we graph that, we see that we get the distribution we worked out by hand from last episode:
Console.WriteLine(sneezed.Histogram());
Console.WriteLine(sneezed.ShowWeights());
Console.WriteLine(joint.Histogram());
Console.WriteLine(joint.ShowWeights());
No|**************************************** Yes|***** No:111 Yes:14 (No, No)|**************************************** (No, Yes)|* (Yes, No)| (Yes, Yes)|*** (No, No):873 (No, Yes):27 (Yes, No):15 (Yes, Yes):85
Aside: Of course I am cheating slightly here because I have not yet implemented the weight function on the combined distribution; we’ll get to that next time!
It might seem slightly vexing that C# requires us to implement a variation on the standard bind operation, but in this case it is actually exactly what we want. Why’s that?
Let’s remind ourselves of how we are notating probability distributions. If we have a collection of possible outcomes of type Cold, we notate that distribution as P(Cold); since Cold has two possibilities, this distribution is made up from two probabilities, P(Cold.Yes) and P(Cold.No) which add up to 100%. We represent this in our type system as IDiscreteDistribution<Cold>
A conditional probability distribution P(Sneezed|Cold) is “given a value from type Cold, what is the associated distribution P(Sneezed)“? In other words, it is Func<Cold, IDiscreteDistribution<Sneezed>>.
What then is P(Cold&Sneezed)? That is our notation for the joint distribution over all possible pairs. This is made up of four possibilities: P(Cold.No & Sneezed.No), P(Cold.No&Sneezed.Yes), P(Cold.Yes&Sneezed.No), and P(Cold.Yes&Sneezed.Yes), which also add up to 100%.
In our type system, this is IDiscreteDistribution<(Cold, Sneezed)>
Now, remember the fundamental law of conditional probability is:
P(A) P(B|A) = P(A&B)
That is, the probability of A and B both occurring is the probability of A occurring, multiplied by the probability of B occurring given that A has.
That is, we can pick any values from those types, say:
P(Cold.Yes) P(Sneezed.Yes|Cold.Yes) = P(Cold.Yes&Sneezed.Yes)
That is, the probability of some value of A and some value of B both occurring is the probability of the value of A occurring multiplied by the probability of the value of B given that the value of A has occurred.
Aside: “multiplication” here is assuming that the probabilities are between 0.0 and 1.0, but again, squint a little and you’ll see that it’s all just weights. In the next episode we’ll see how to compute the weights as integers by thinking about how to do the multiplication in fractions.
We’ve implemented P(A) as IDiscreteDistribution<A>, we’ve implemented P(B|A) as Func<A, IDiscreteDistribution<B>>, and P(A&B) as IDiscreteDistribution<(A, B)>.
We have a function Joint<A, B> that takes the first two and gives you the third, and if you work out the math, you’ll see that the probabilities of each member of the joint distribution that results are the products of the probabilities given from the prior and the likelihood. Multiplication of a prior probability by a likelihood across all members of a type is implemented by SelectMany.
Coming up on FAIC: We’ll work out the weights correctly, and that will enable us to build an optimized SelectMany implementation.