You might recall that before my immensely long series on ways we could make C# a probabilistic programming language, I did a short series on how we can automatically computed the exact derivative in any direction of a real-valued function of any number of variables for a small cost, by using dual numbers. All we need is for the function we are computing to be computed by addition, subtraction, multiplication, division and exponentiation of functions whose derivatives are known, which is quite a lot of possible functions.
There is a reason why I did that topic before “Fixing Random”, but sadly I never got to the connection between differential calculus and sampling from an arbitrary distribution. I thought I might spend a couple of episodes sketching out how it is useful to use automatic differentiation when trying to sample from a distribution. I’m not going to write the code; I’ll just give some of the “flavour” of the algorithms.
Before I get into it, a quick refresher on the Metropolis algorithm. The algorithm is:
- We have a probability distribution function that takes a point and returns a double that is the “probability weight” of that point. The PDF need not be “normalized”; that is, the area under the curve need not add up to 1.0. We wish to generate a series of samples that conforms to this distribution.
- We choose a random “initial point” as the current sample.
- We randomly choose a candidate sample from some distribution based solely on the current sample.
- If the candidate is higher weight than current, it becomes the new current and we yield the value as the sample.
- If it is lower weight, then we take the ratio of candidate weight to current weight, which will be between 0.0 and 1.0. We flip an unfair coin with that probability of getting heads. Heads, we accept the candidate, tails we reject it and try again.
- Repeat; choose a new candidate based on the new current.
The Metropolis algorithm is straightforward and works, but it has a few problems.
- How do we choose the initial point?
Since Metropolis is typically used to compute a posterior distribution after an observation, and we typically have the prior distribution in hand, we can use the prior distribution as our source of the initial point.
- What if the initial point is accidentally in a low-probability region? We might produce a series of unlikely samples before we eventually get to a high-probability current point.
We can solve this by “burning” — discarding — some number of initial samples; we waste computation cycles so we would like the number of samples it takes to get to
“convergence” to the true distribution to be small. As we’ll see, there are ways we can use automatic differentiation to help solve this problem.
- What distribution should we use to choose the next candidate given the current sample?
This is a tricky problem. The examples I gave in this series were basically “choose a new point by sampling from a normal distribution where the mean is the current point”, which seems reasonable, but then you realize that the question has been begged. A normal distribution has two parameters: the mean and the standard deviation. The standard deviation corresponds to “how big a step should we typically try?” If the deviation is too large then we will step from high-probability regions to low-probability regions frequently, which means that we discard a lot of candidates, which wastes time. If it is too small then we get “stuck” in a high-probability region and produce a lot of samples close to each other, which is also bad.
Basically, we have a “tuning parameter” in the standard deviation and it is not obvious how to choose it to get the right combination of good performance and uncorrelated samples.
These last two problems lead us to ask an important question: is there information we can obtain from the weight function that helps us choose a consistently better candidate? That would lower the time to convergence and might also result in fewer rejections when we’ve gotten to a high-probability region.
I’m going to sketch out one such technique in this episode, and another in the next.
As I noted above, Metropolis is frequently used to sample points from a high-dimensional distribution; to make it easier to understand, I’ll stick to one-dimensional cases here, but imagine that instead of a simple curve for our PDF, we have a complex multidimensional surface.
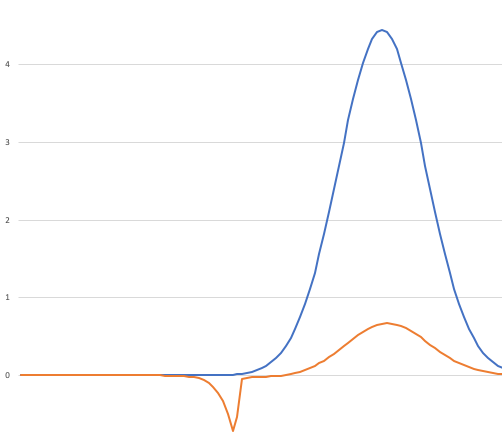
Let’s use as our motivating example the mixture model from many episodes ago:
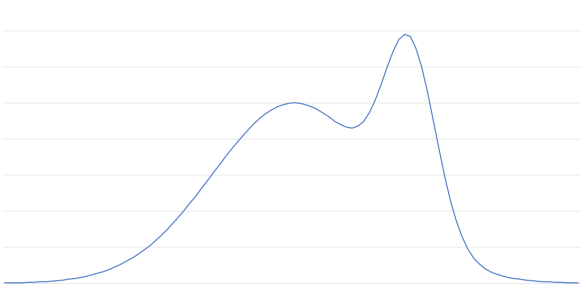
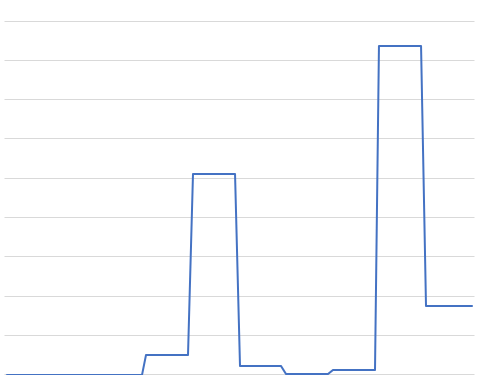
Of course we can sample from this distribution directly if we know that it is the sum of two normal distributions, but let’s suppose that we don’t know that. We just have a function which produces this weight. Let me annotate this function to say where we want to go next if the current sample is in a particular region.
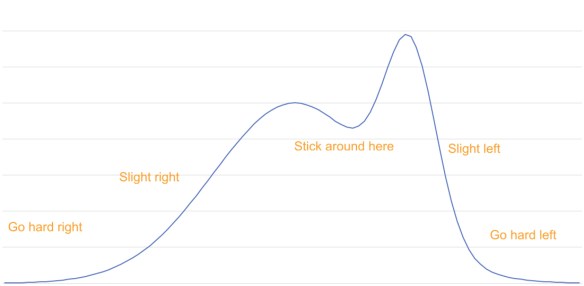
I said that we could use the derivative to help us, but it is very unclear from this diagram how the derivative helps:
- The derivative is small and positive in the region marked “go hard right” and in the immediate vicinity of the two peaks and one valley.
- The derivative is large and positive in the “slight right” region and to the left of the tall peak.
- The derivative is large and negative in the “slight left” region and on the right of the small peak.
- The derivative is small and negative in the “hard left” region and in the immediate vicinity of the peaks and valley.
No particular value for the derivative clearly identifies a region of interest. It seems like we cannot use the derivative to help us out here; what we really want is to move away from small-area regions and towards large-area regions.
Here’s the trick.
Ready?
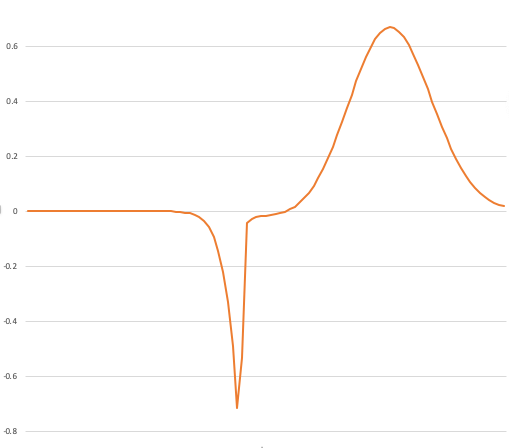
I’m going to graph the log of the weight function below the weight function:
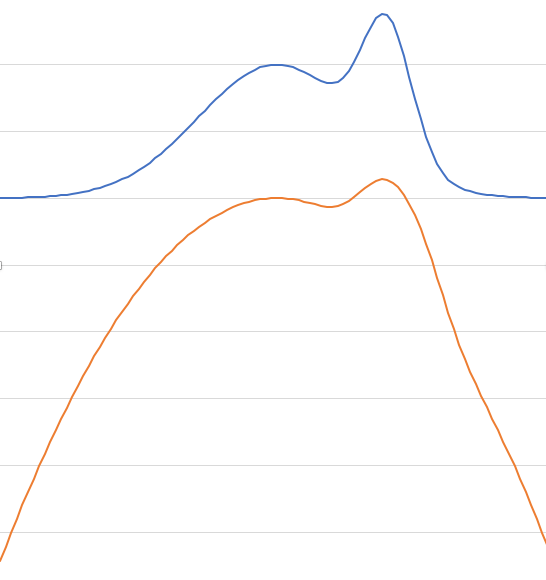
Now look at the slope of the log-weight. It is very positive in the “move hard right” region, and becomes more and more positive the farther left we go! Similarly in the “move hard left” region; the slope of the log-weight is very negative, and becomes more negative to the right.
In the “slight right” and “slight left” regions, the slope becomes more moderate, and when we are in the “stay around here” region, the slope of the log-weight is close to zero. This is what we want.
(ASIDE: Moreover, this is even more what we want because in realistic applications we often already have the log-weight function in hand, not the weight function. Log weights are convenient because you can represent arbitrarily small probabilities with “normal sized” numbers.)
We can then use this to modify our candidate proposal distribution as follows: rather than using a normal distribution centered on the current point to propose a candidate, we compute the derivative of the log of the weight function using dual numbers, and we use the size and sign of the slope to tweak the center of the proposal distribution.
That is, if our current point is far to the left, we see that the slope of the log-weight is very positive, so we move our proposal distribution some amount to the right, and then we are more likely to get a candidate value that is in a higher-probability region. But if our current point is in the middle, the slope of the log-weight is close to zero so we make only a small adjustment to the proposal distribution.
(And again, I want to emphasize: realistically we would be doing this in a high-dimensional space, not a one-dimensional space. We would compute the gradient — the direction in which the slope increases the most — and head that direction.)
If you work out the math, which I will not do here, the difference is as follows. Suppose our non-normalized weight function is p.
- In the plain-vanilla proposal algorithm we would use as our candidate distribution a normal centered on current with standard deviation s.
- In our modified version we would use as our candidate distribution a normal centered on current + (s / 2) * ∇log(p(current)), and standard deviation s.
Even without the math to justify it, this should seem reasonable. The typical step in the vanilla algorithm is on the order of the standard deviation; we’re making an adjustment towards the higher-probability region of about half a step if the slope is moderate, and a small number of steps if the slope is severe; the areas where the slope is severe are the most unlikely areas so we need to get out of them quickly.
If we do this, we end up doing more math on each step (to compute the log if we do not have it already, and the gradient) but we converge to the high-probability region much faster.
If you’ve been following along closely you might have noticed two issues that I seem to be ignoring.
First, we have not eliminated the need for the user to choose the tuning parameter s. Indeed, this only addresses one of the problems I identified earlier.
Second, the Metropolis algorithm requires for its correctness that the proposal distribution not ever be biased in one particular direction! But the whole point of this improvement is to bias the proposal towards the high-probability regions. Have I pulled a fast one here?
I have, but we can fix it. I mentioned in the original series that I would be discussing the Metropolis algorithm, which is the oldest and simplest version of this algorithm. In practice we use a variation on it called Metropolis-Hastings which adds a correction factor to allow non-symmetric proposal distributions.
The mechanism I’ve sketched out today is called the Metropolis Adjusted Langevin Algorithm and it is quite interesting. It turns out that this technique of “walk in the direction of the gradient plus a random offset” is also how physicists model movements of particles in a viscous fluid where the particle is being jostled by random molecule-scale motions in the fluid. (That is, by Brownian motion.) It’s nice to see that there is a physical interpretation in what would otherwise be a very abstract algorithm to produce samples.
Next time on FAIC: The fact that we have a connection to a real-world physical process here is somewhat inspiring. In the next episode I’ll give a sketch of another technique that uses ideas from physics to improve the accuracy of a Metropolis process.