
Last time I gave a simple C# implementation of the first-order anti-unification algorithm. This is an interesting algorithm, but it’s maybe not so clear why anti-unification is useful at all. It’s pretty clear why unification is interesting: we have equations that need solving! But why would you ever need to have two (or more) trees that need anti-unifying to a more general tree?
Here’s a pair of code changes:
dog.drink(); —becomes—> if (dog != null) dog.drink();
dog.bark(); —becomes—> if (dog != null) dog.bark();
Now here’s the trick. Suppose we represent each of these code changes as a tree. The root has two children, “before” and “after”. The child of each side is the abstract syntax tree of the before and after code fragment, so our two trees are:
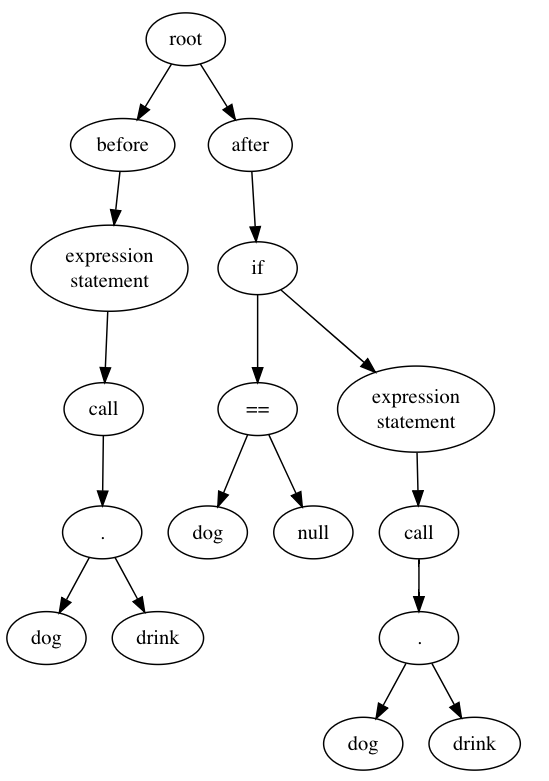

Now suppose we anti-unify those two trees; what would we get? We’d get this pattern:
dog.h0(); —> if (dog != null) dog.h0();
Take a look at that. We started with two code changes, anti-unified them, and now we have a template for making new code edits! We could take this template and write a tool that transforms all code of the form “an expression statement that calls a method on a variable called dog” into the form “an if statement that checks dog for null and calls the method if it is not null”.
What I’m getting at here is: if we have a pair of small, similar code edits, then we can use anti-unification to deduce a generalization of those two edits, in a form from which we could then build an automatic refactoring.
But what if we have three similar code edits?
edit 1: dog.drink(); —> if (dog != null) dog.drink();
edit 2: dog.bark(); —> if (dog != null) dog.bark();
edit 3: cat.meow(); —> if (cat != null) cat.meow();
Let’s take a look at the pairwise anti-unifications:
1 & 2: dog.h0(); —> if (dog != null) dog.h0();
1 & 3: h1.h0(); —> if (h1 != null) h1.h0();
2 & 3: the same.
Anti-unifying the first two makes a more specific pattern than any anti-unification involving the third. But the really interesting thing to notice here is that the anti-unifications of 1&3 and 2&3 is itself a generalization of the anti-unification of 1&2!
Maybe that is not 100% clear. Let’s put all the anti-unifications into a tree, where the more general “abstract” patterns are at the top, and the individual “concrete” edits are at the leaves:
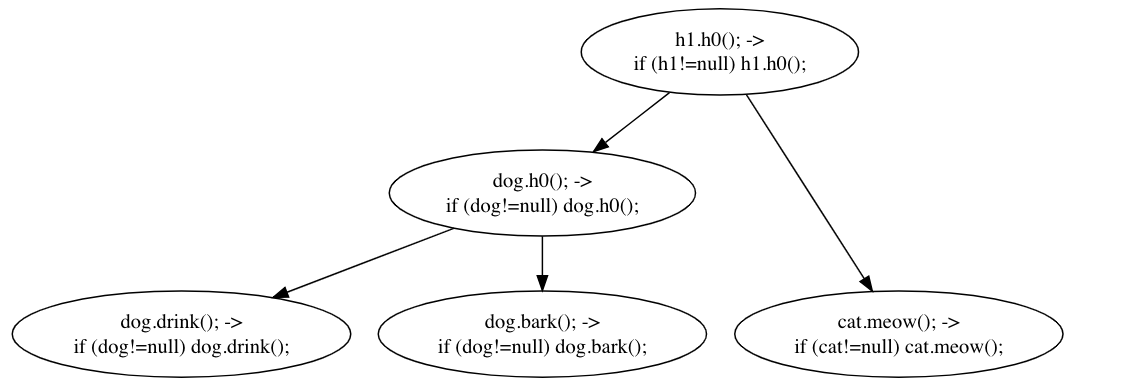
Each parent node is the result of anti-unifying its children. This kind of tree, where the leaves are specific examples of a thing, and each non-leaf node is a generalization of everything below it, is called a dendrogram, and they are very useful when trying to visualize the output of a hierarchical clustering algorithm.
Now imagine that we took hundreds, or thousands, or hundreds of thousands of code edits, and somehow managed to work out a useful dendrogram of anti-unification steps for all of them. This is a computationally difficult problem, and in a future episode, I might describe some of the principled techniques and unprincipled hacks that you might try to make it computationally feasible. But just suppose for the moment we could. Imagine what that dendrogram would look like. At the root we’d have the most general anti-unification of our before-to-after pattern:
h0 —> h1
Which is plainly useless. At the leaves, we’d have all of the hundreds of thousands of edits, which are not useful in themselves. But the nodes in the middle are pure gold! They are all the common patterns of code edits that get made in this code base, in a form that you could turn into a refactoring or automatic fix template. The higher in the tree they are, the more general they are.
You’ve probably deduced by now that this is not a mere flight of fancy; I spent eight months working on a tiny research team to explore the question of whether this sort of analysis is possible at the scale of a modern large software repository, and I am pleased to announce that indeed it is!
We started with a small corpus of code changes that were made in response to a static analysis tool (Infer) flagging Java code as possibly containing a null dereference, built tools to extract the portions of the AST which changed, and then did a clustering anti-unification on the corpus to find patterns. (How the AST extraction works is also very interesting; we use a variation on the Gumtree algorithm. I might do a blog series about that later.) It was quite delightful that the first things that popped out of the clustering algorithm were patterns like:
h0.h1(); —> if (h0 != null) h0.h1();
h0.h1(); —> if (h0 == null) return; h0.h1();
h0.h1(); —> if (h0 == null) throw …; h0.h1();
if (h0.h1()) h2; —> if (h0 != null && h0.h1()) h2;
and a dozen more variations. You might naively think that removing a null dereference is easy, but there are a great many ways to do it, and we found most of them in the first attempt.
I am super excited that this tool works at scale, and we are just scratching the surface of what we can do with it. Just a few thoughts:
- Can it find patterns in bug fixes more complex than null-dereference fixes?
- Imagine for example if you could query your code repository and ask “what was the most common novel code change pattern last month?” This could tell you if there was a large-scale code modification but the developer missed an example of it. Most static analysis tools are of the form “find code which fails to match a pattern”; this is a tool for finding new patterns and the AST operations that apply the pattern!
- You could use it as signal to determine if there are new bug fix patterns emerging in the code base, and use them to drive better developer education.
- And many more; if you had such a tool, what would you do with it? Leave comments please!
The possibilities of this sort of “big code” analysis are fascinating, and I was very happy to have played a part in this investigation.
UPDATE: I’ve posted a follow-up now that we’ve released a video and a paper about this work.
I have a lot of people to thank: our team leader Satish, who knows everyone in the code analysis community, our management Erik and Joe who are willing to take big bets on unproven technology, my colleagues Andrew and Johannes, who hit the ground running and implemented some hard algorithms and beautiful visualizations in very little time, our interns Austin and Waruna, and last but certainly not least, the authors of the enormous stack of academic papers I had to read to figure out what combination of techniques might work at FB scale. I’ll put some links to some of those papers below.
- An Algorithm of Generalization in Positive Supercompilation (which lays out the anti-unification algorithm very concisely, though for a completely different purpose than I’ve used it for here.)
- Anti-unification algorithms and their applications in program analysis
- Fine-grained and Accurate Source Code Differencing
- History Driven Program Repair
- Learning Quick Fixes from Code Repositories
- Learning Syntactic Program Transformations from Examples
- Mining Fix Patterns For FindBugs Violations
- RTED: A Robust Algorithm for the Tree Edit Distance
- Static Automated Program Repair for Heap Properties

I was sure that the end of this series is about how to find the most general type interface that expressions need. Boy, was I wrong…
I could also see anti-unification used as a tool to extract commonly repeated code into helper functions.
I would use it automate large scale refactorings that fall outside of the general refactorings that most tools such as resharper offer. I’ve had a few refactorings where it didn’t match any of Resharper’s options, but there was a pattern to it. It could probably be automated but there wasn’t enough changes to make it worth my while. So it generally boils down to maybe some global search and replace with regexes and fixing up the rest of the code.
Seems like with this tool it might be possible to change a few areas of the code to give it examples, have it analyze that and be able to do the rest of the code.
Do you know R#’s structural search & replace feature? https://www.jetbrains.com/help/resharper/Navigation_and_Search__Structural_Search_and_Replace.html It’s really mighty. The output of Eric’s tool can maybe even be translated directly to R# SSRs.
A possible use would be to run it on a large repo of repos like github and glean ideas for special syntax to improve existing languages, or as starting point to design a new language where repetitive and systematic fix isn’t needed.. such a repetitive fix can be interpreted as a language defect, making it somewhat frequent that incorrect construction is used in the first place (I imagine because shorter) e.g. Preventing reference type to ever be null unless specified is a wonderful idea I can’t wait to use in c# 8.0 (hopefully). In another direction: maybe frequently used composition patterns can often be solidified in a particular monad (in the case of your example the Maybe monad), but there must be others. Another idea is produce a recommandation system to the developer like: ‘code like A often gets rewritten like B (x% of cases on github) or C (y% of cases on github) click here to apply transformation B and here for C’ 🙂
Those are all great use cases!
Pingback: Applying machine learning to coding itself | Fabulous adventures in coding
Another possible use would be upgrading projects to new language or framework versions.
Tools like R# can suggest ways to use new language features, but this could automatically catch a lot more changes: updating project files, installers, and other things that aren’t quite source code, or replacing platform-specific libraries with the new platform’s equivalents.