
Last time on FAIC I introduced a fun variation on complex numbers called “dual numbers” consisting of a value “plus a tiny bit” notated as ε, where the really tiny part has the interesting property that ε2 is zero.
Well, enough chit-chat; let’s implement them.
You know what, just for grins I’m going to make this look a bit more like math, and a bit more concise while we’re at it:
using ⅅ = Dual;
using ℝ = System.Double;
(Unfortunately 𝔻 is not a legal identifier in C#.)
A dual is logically a value that consists of two doubles, so it makes sense to represent them as an immutable value type:
public struct Dual : IComparable<Dual>
{
public ℝ Real { get; }
public ℝ Epsilon { get; }
public ℝ r => this.Real;
public ℝ ε => this.Epsilon;
I got so sick of typing out “Real” and “Epsilon” that I had to make these helper properties, even though they do not meet C# naming guidelines. Guidelines are guidelines, not rules!
Notice also that, fun fact, C# lets you use any non-surrogate-pair Unicode character classified as a letter in an identifier.
The constructor is as you’d expect, and I’m going to make a helper property for 0+1ε:
public Dual(ℝ real, ℝ epsilon)
{
this.Real = real;
this.Epsilon = epsilon;
}
public static ⅅ EpsilonOne = new ⅅ(0, 1);
The math is as we’ve discussed:
public static ⅅ operator +(ⅅ x) => x;
public static ⅅ operator –(ⅅ x) => new ⅅ(–x.r, –x.ε);
public static ⅅ operator +(ⅅ x, ⅅ y) =>
new ⅅ(x.r + y.r, x.ε + y.ε);
public static ⅅ operator –(ⅅ x, ⅅ y) =>
new ⅅ(x.r – y.r, x.ε – y.ε);
public static ⅅ operator *(ⅅ x, ⅅ y) =>
new ⅅ(x.r * y.r, x.ε * y.r + x.r * y.ε);
public static ⅅ operator /(ⅅ x, ⅅ y) =>
new ⅅ(x.r / y.r, (x.ε * y.r – x.r * y.ε) / (y.r * y.r));
So easy!
UPDATE: I was WRONG WRONG WRONG in the section which follows.
An earlier version of this episode suggested that we implement comparisons on dual numbers as “compare the real parts; if equal, compare the epsilon parts”. But upon reflection, I think that’s not right. One of the characteristics of dual numbers that we like is that “lifting” a computation on reals to dual numbers produce the same “real part” in the result. Suppose we have:
static bool Foo(ℝ x) => x > 2.0;
Then we reasonably expect that
static bool Foo(ⅅ x) => x > 2.0;
agrees with it, no matter what value we have for epsilon.
So I’m going to tweak the code so that we compare only real parts.
Resuming now the original episode…
My preference is to implement the logic in one place in a helper, and then call that helper everywhere:
private static int CompareTo(ⅅ x, ⅅ y) =>
x.r.CompareTo(y.r);
public int CompareTo(ⅅ x) =>
CompareTo(this, x);
public static bool operator <(ⅅ x, ⅅ y) =>
CompareTo(x, y) < 0;
public static bool operator >(ⅅ x, ⅅ y) =>
CompareTo(x, y) > 0;
public static bool operator <=(ⅅ x, ⅅ y) =>
CompareTo(x, y) <= 0;
public static bool operator >=(ⅅ x, ⅅ y) =>
CompareTo(x, y) >= 0;
public static bool operator ==(ⅅ x, ⅅ y) =>
CompareTo(x, y) == 0;
public static bool operator !=(ⅅ x, ⅅ y) =>
CompareTo(x, y) != 0;
public bool Equals(ⅅ x) =>
CompareTo(this, x) == 0;
public override bool Equals(object obj) =>
obj is ⅅ x && CompareTo(this, x) == 0;
And finally, a few loose ends. It would be nice to be able to convert to Dual from double automatically, and we should also override ToString and GetHashCode just to be good citizens:
public static implicit operator ⅅ(ℝ x) => new ⅅ(x, 0);
public override string ToString() => $”{r}{(ε<0.0?“”:“+”)}{ε}ε”;
public override int GetHashCode() => r.GetHashCode();
Super, that was really easy. And now we can take any old method that does math on doubles, and make it do math on Duals. Suppose we’ve got this little guy, that computes x4+2x3-12x2-2x+6:
static ℝ Compute(ℝ x) =>
x * x * x * x + 2 * x * x * x – 12 * x * x – 2 * x + 6;
If we just turn all the doubles into Duals:
static ⅅ Compute(ⅅ x) =>
x * x * x * x + 2 * x * x * x – 12 * x * x – 2 * x + 6;
Then we have the same function, but now implemented in the dual number system. This:
Console.WriteLine(Compute(1.0 + Dual.EpsilonOne));
Produces the output -5-16ε, which agrees with the original method in the real part, and is -16 in the epsilon part. Apparently computing that polynomial with one plus a tiny amount gives us -5, plus -16 “more tiny amounts”.
Hmm.
You know what, just for grins I’m going to compute this function from -4.5+εto 3.5+ε and then graph the real and epsilon parts of the output of our “dualized” function.
The blue line is the real part, the orange line is the epsilon part. As we expect, the blue line corresponds to the original polynomial. But the orange line looks suspiciously familiar…
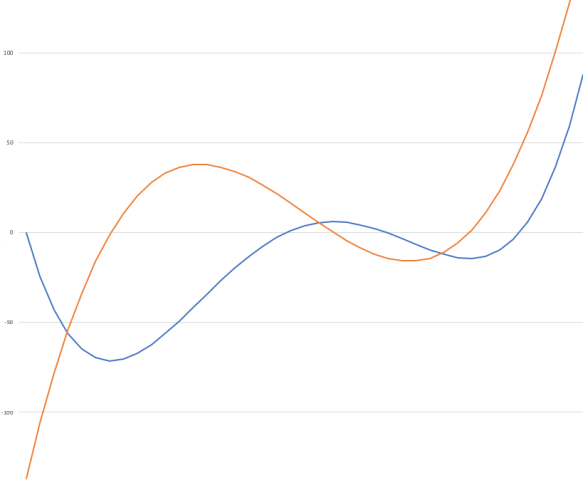
HOLY GOODNESS THE ORANGE LINE IS ZERO WHERE THE BLUE LINE IS FLAT.
The epsilon part is the derivative of the polynomial!
Next time on FAIC: How’d that happen?

This follows from the definition of the derivative, isn’t it?
f(x0 + h) = f(x0) + Ah + o(h)
where h in your case is ε and o(h) = ε*ε = 0, and A is a derivative by definition.
This may be a dumb question, but why isn’t 𝔻 valid in C# identifiers? According to https://www.compart.com/en/unicode/U+1D53B, it’s classified as an uppercase letter (class Lu) and it’s not a combined mark.
Is it just because it requires two UTF-16 code units? The language specification doesn’t seem to call this out explicitly (or I don’t know how to read the spec), but it does say an identifier may contain “A unicode-escape-sequence representing a character of classes Lu, Ll, Lt, Lm, Lo, or Nl” and then about escape sequences: “Since C# uses a 16-bit encoding of Unicode code points in character and string values, a Unicode code point in the range U+10000 to U+10FFFF is represented using two Unicode surrogate code units. Unicode code points above U+FFFF are not permitted in character literals.” so perhaps that implies that only 16-bit code units are valid in identifiers as well.
https://www.ecma-international.org/publications/files/ECMA-ST/ECMA-334.pdf#page=41
There are a number of oddities around precisely how C# handles Unicode text. I believe the intention was that code points represented by surrogate pairs in UTF-16 be made illegal in identifiers. I would not be at all surprised if the spec was unclear on that point.
I find it quite vexing that the Unicode consortium did not standardize the “chalkboard capital” versions of all the capital Latin-alphabet letters in the first go-round, instead of just doing the ones that appear commonly in math papers.
Here are Roslyn issues about adding support for surrogate pairs in identifiers, with the “help wanted” label: https://github.com/dotnet/roslyn/issues/13474, https://github.com/dotnet/roslyn/issues/9731.
It seems this is considered a bug, but not a priority for MS. So it probably won’t be fixed anytime soon, unless someone steps in.
The mathematician in me is obliged to point out that, while it may make sense for this particular case, comparison operators do not make sense in general for value pairs. Specifically, ℂ (on which you based your formulas) is not an ordered set.
Your case, though, is a real plus a tiny real, which yields a real, so it works.
Well if we are talking to the mathematician in you, then let’s be precise. The standard order on the reals is a total order. The reals and the complexes have the same cardinality and there are infinitely many injective functions from reals to complexes. Therefore there are infinitely many total orders on the complexes. Pretty much none of them are *useful*, but they *exist*. We can make up lots of ways to order complexes; that we have not found a compelling use case for any of them is a fact about what we find useful.
Regardless though, I am thinking it might have been a bad idea both pedagogically and logically to introduce comparison operators. The comparison operators violate the principle that “X op Y” on reals gives the same result when lifted to duals. And I don’t need them.
I am bothered by something you’ve apparently glossed over in your comparisons. Specifically, are we to understand that ε is so tiny, that no matter what the coefficient of it is, a real plus or minus ε times that coefficient can never reach the next representable real number in the respective direction (depending on positive or negative coefficient)?
For example, in your comparisons, you assume, and your comparison functions assert, that 1+ε is less than 2-ε (i.e. ε coefficients of 1 and -1, respectively). But if ε is greater than 0.5, this doesn’t seem to be true.
I would find the discussion above more complete if there was an explanation (possibly hinging on the fact that ε squared is zero?) for why the comparisons do in fact work correctly in spite of this.
In the precious post Eric described ε as “[…] much smaller than one, and really, really small compared to the original quantity.” and “Maybe […] one part in a googolplex, or whatever” and “I’m being deliberately vague and hand-wavy here; just run with it.”
So please run, and don’t stop and think too much about it. 😉
ε is real infinitesimal. It comes from definition of derivative (that’s why the graph of ε coefficient is the graph of derivative)
https://en.wikipedia.org/wiki/Generalizations_of_the_derivative
look af first formula. h (ε) -> 0. So it can’t be 0.5 if only “real” part more then 10.
Neither of you are really _explaining_ anything though. The “0.5” is just an example. Assuming ε is a non-zero real number, it doesn’t matter what it is; I can always pick a coefficient large enough that when multiplied by ε, I can bridge the gap between two other real numbers.
I don’t doubt that Eric’s approach is valid. My concern is that having come to the implementation part, the hand-waving no longer is sufficient. There should be a genuine explanation here as to why one’s intuition about real numbers no longer applies.
Plainly ε cannot be any real number because no real number has the property that it is both non zero and squares to zero. Just like i is not a real number.
What you need to do is ignore the crazy, vague, hand-waving intuitions and just follow the rules. A dual number is not a sum of two things at all. Neither is a complex number. Both duals and complexes are a pair of real numbers, and a bunch of operators defined to operate on those pairs. We motivate those rules with the notion that ε “behaves like it is really small”, but that motivation is irrelevant; we cannot use it to prove theorems. The only things we can use to prove theorems are our definitions for how the operators behave on the pairs.
As I noted in a comment above, I’m regretting introducing comparison operators unnecessarily. I don’t need them for my purposes here, and I am thinking I might have gotten them wrong. You can imagine cases where we lift an algorithm on reals to duals and the algorithm has different behavior because comparisons on reals that used to be equal are now unequal.
In my head, ε represents the odds of winning the Powerball lottery if I buy a ticket. If I don’t buy a ticket, my odds are 0. If I buy a ticket, my odds are positive, but infinitesimally small. If I buy two tickets for the same drawing, my odds are 2ε, but still infinitesimally small. The odds of me hitting the Powerball twice in a row are effectively zero (ε-squared).
What a charming analogy! I may steal that. 🙂
Nit: the ToString method is a bit off. It’s currently ‘{(ε<0.0?"":"+")}' but should be '{(ε<0.0?"-":"+")}'
Really? Did you try your proposed “fix”?
Now that you changed Equals to only compare the real part, shouldn’t GetHashCode be changed too?
Yes! Good catch.
Pingback: Dual numbers, part 3 | Fabulous adventures in coding
Is the polynomial displaying incorrectly for me or is there an extra ‘-‘ between the 12 and the x?
I see “x4+2×3-12-x2-2x+6” (copy/paste removed the super script for the exponents.)
should it be: “x4+2×3-12×2-2x+6” ?
Fixed! Thanks.
“Notice also that, fun fact, C# lets you use any non-surrogate-pair Unicode character classified as a letter in an identifier.”
“There are a number of oddities around precisely how C# handles Unicode text. I believe the intention was that code points represented by surrogate pairs in UTF-16 be made illegal in identifiers. I would not be at all surprised if the spec was unclear on that point.”
Well, C# (the language) permits letters that are represented as surrogate pairs. It just has never been implemented (in the compiler). The C# specification doesn’t assume that the program input is represented as UTF-16 at any point, so it has no reason to add any restriction relating to surrogate pairs. The spec defers to the Unicode Standard for details, and the Unicode Standard certainly permits letters that happen to be encoded as surrogate pairs.
See
https://github.com/dotnet/roslyn/issues/9731
https://github.com/dotnet/roslyn/issues/13474
https://github.com/dotnet/roslyn/issues/13560
These issues are “up for grabs”, so any competent compiler engineer who happened to be one of the authors of the Roslyn compiler (hint hint) could offer a fix.
I’ll get right on that in my copious spare time! 🙂